Gero Scholz, Ralf S. Engelschall
Wir fragen uns, welche Kompetenzen zur Bewältigung der im Teil 1 beschriebenen Disruption benötigt werden und wie wir diese Kompetenzen vermitteln können.
Wir denken dabei an die Lehre des Fachinformatikers, das Studium an der Hochschule und an die innerbetriebliche Schulung und Weiterbildung. Der Einfachheit halber sprechen wir allerdings von "dem Studi", wenn es um die Adressat*innen unserer Überlegungen geht.
1) Cheating off-limits!
Wer heute Abitur macht, hat in aller Regel bereits Erfahrung mit AI zur Vorbereitung auf die Prüfung gesammelt. Wer ein Informatik-nahes Fach studieren will, hat sicher schon lauffähige kleine Systeme mit Agentic Coding erzeugen lassen. Unsere erste Aufgabe in der Lehre ist es daher, das Problembewusstsein dafür zu schaffen, dass und warum ingenieurmäßiges Vorgehen ein hohes Maß an Planung, Umsicht und strukturelle Vorgaben erfordert.
Mit unserem ersten Vorschlag holen wir die Studis dort ab, wo sie stehen. Sie sollen in Gruppen im Wettbewerb eine verhältnismäßig kleine Aufgabe auf irgendeinem Weg lösen, etwa durch direkten Auftrag an die AI oder durch Anpassung einer Lösung, die man im Web gefunden hat. Die Studis sollen sich so fühlen wie im Beruf: Ein Kunde verlangt etwas und sie müssen irgendwie liefern. Die Aufgabe ist so formuliert, dass es fertige Teil-Lösungen dafür im Web gibt, enthält aber ein paar zusätzliche Vorgaben, die eine individuelle Anpassung erfordern. Der Einfachheit halber könnte es ein Spiel sein wie five-in-a-row, das wir jedoch auf mehrere Arten abwandeln, z.B. durch spezielle Layout-Wünsche, durch zusätzliche Spielregeln, durch Zeitüberwachung (ähnlich wie Blitzschach), durch Hintergrundmusik, durch blockierte Felder auf dem Spielbrett usw.
Zu Beginn wird allen Teilnehmern mitgeteilt, dass hinterher eine Wertung nach fünf Kriterien stattfindet:
- die Einhaltung der Anforderungen (User Interface, Regelbefolgung, Spielstärke, Umsetzung aller geforderten Features)
- das Verständnis der Studis für die Implementierung, gemessen durch bestimmte Fragen zu ihrem Ergebnis
- den Zeitaufwand, den sie benötigen, um eine sehr kleine (vorläufig noch unbekannte) Änderung am UI manuell durchzuführen, ohne dass sie vorher die AI irgendetwas fragen dürfen (z.B. Farbe der Spielsteine ändern)
- den Zeitaufwand, den sie zusammen mit der AI benötigen, um ein weiteres zuvor unbekanntes Feature in ihre Lösung einzubauen (Wenn der Computergegner einen Gewinnzug hat, soll er ihn in 20% der Fälle absichtlich "übersehen")
- die Punktzahl, die die Teilnehmer aller anderen Gruppen anonym für einen Vortrag (10 Minuten) vergeben, in dem die Gruppe erläutert, welchen Weg sie gewählt hat (z.B. auch ihre Prompts an die AI), wie zufrieden sie selbst mit dem Prozess und dem Ergebnis war und wie gut sie die Struktur ihres Programms erläutern konnten
Die Laufzeit des Projekts könnte vier Wochen betragen. In dieser Zeit geben die Lehrenden Hilfestellung dazu, wie man AI möglichst geschickt einsetzt und welche typischen Probleme entstehen. Sie vermitteln den Studis außerdem ein Gefühl dafür, warum ihre Spielanwendung "klein" ist (lokale Ausführung, single User, keine persistenten Daten, usw.) und wie groß reale Systeme sein können und warum große Software-Projekte immer mal wieder scheitern.
2) Lernen am (nicht ganz) fertigen System
Während der erste Vorschlag vermutlich sogar mit Anfängern realisierbar wäre, richtet sich unser zweiter Vorschlag an Studis, die solide Programmierkenntnisse und ein gewisses Verständnis für Software-Architektur erworben haben, sei es durch Vorlesung, Übung oder selbst entwickelte Anwendungen.
Wir konfrontieren sie mit einem mittelgroßen realen Muster-System. Dieses System hat eine leicht verständliche Fachlichkeit, bei der jeder mitreden kann. Es muss unter Gesichtspunkten der Software-Architektur einigermaßen professionell sein und es umfasst Plan-Build-Run, zielt also auf den gesamten Life-Cycle, incl. Change Requests, Versionsverwaltung, Datenmigration, Rückwärtskompatibilität, Build-System, Performance-Monitoring und Software Updates im Feld.
Genau genommen geht es nicht um ein einziges Muster-System, sondern um einen Baukasten, der auf typische Anwendungsgebiete und die dort am häufigsten vorkommenden Architekturen und Frameworks zielt. Zwei Beispiele:
- Ein betriebliches Informationssystem mit Web UI, Anwendungslogik und Datenbank auf dem Server
- Ein technisches System, das Sensoren und Aktoren besitzt, autonom agiert, aber auch Serververbindungen für zentrales Data-Logging und Remote Updates herstellt
Unter dem Acronym AIDE (AI for Development Engineers) bereiten wir im Moment die erste solche Muster-Anwendung vor. Wir haben mit einem Online-Quiz begonnen (https://github.com/aide-examples/aide-quiz), welches aus technischer Sicht deutliche Wesenszüge eines betrieblichen Informationssystems aufweist. Der zweite Schritt wird voraussichtlich ein Solarwechselrichter für eine Inselanlage (aide-solar) sein. Neben solchen Systemen mittlerer Größe sind wir im technischen Bereich auch offen für etwas kleinere Beispiele, etwa innerhalb des "Shelly"-Ökosystems. Wir laden interessierte Leser ein, sich daran zu beteiligen.
So wie ein KFZ-Mechatroniker schon in seiner Ausbildung mit fertigen Autos konfrontiert ist, in denen sich tausende Jahre von Ingenieurwissen materialisiert haben, so müssen Informatiker direkt im Anschluss an erworbenes Grundlagenwissen den Umgang mit komplexen Systemen erlernen. Es geht darum, Verständnis auf einer "mittleren Flughöhe" zu trainieren, ohne dass man jede Code-Zeile verstehen will.
Der große Vorteil, den uns die AI beim Lernen am Modell bietet, besteht in ihrer Fähigkeit, Strukturen zu erkennen, zu dokumentieren und Fragen dazu zu beantworten. Von jemandem zu verlangen, er möge 20.000 Lines of Code lesen, wäre absurd. Er soll mit dem System herumspielen, die Hilfetexte lesen, dann die Spezifikationen und Testfälle. Dann ein paar vorbereitete Change Requests lesen. Er sollte sich ruhig auch eigene Change-Requests ausdenken. Wir sind hier zwar nicht bei "Wünsch-Dir-Was", sondern bei "So-Ist-Das", aber es entfaltet starke Motivation, eigene Ideen zu formulieren mit der Hoffnung, dass man lernt, wie sie umgesetzt werden können.
Danach kann er sich von der AI die Struktur des Systems erklären lassen, UML-Dokumente ansehen und irgendwann auch in formale Notationen ausführbarer Artefakte eintauchen. Er kann mit Mikro-Änderungen beginnen, z.B. CSS und HTML ändern und auch ein paar Zeilen Javascript Code.
Dann erhält der Studi die Aufgabe, eine kleine fachliche Erweiterung einzubauen. Er darf den Agenten alles fragen, um herauszufinden, an welchen Stellen dafür etwas verändert werden muss, aber er darf die AI nicht bitten, Code zu erzeugen.
Die Aufgaben zur Veränderung sind so formuliert, dass sie auf bestimmte Teile der Architektur fokussieren. Und sie sind gleichzeitig so formuliert, dass sie Anlass bieten, Grundlagenwissen zu vertiefen.
Das bringt uns zur nächsten These.
3) Grundlagen: systematisch und ad-hoc!
Nachhaltiges Lernen setzt eine Motivation voraus, die am besten aus einem konkreten Problemlösungsbedürfnis herauskommt.
Beispiel:
Ausgangssituation: Das Quiz-System bietet die Möglichkeit, in eine Fragestellung Bildmaterial zu integrieren. Die entsprechenden Medien werden auf dem Server in einem Verzeichnis des Filesystems gespeichert. Durch "Zufall" stellt sich nachträglich heraus, dass bestimmte Sonderzeichen in Datei- und Verzeichnisnamen erhebliche technische Probleme verursachen. Außerdem besteht der Verdacht, dass manche Dateien "gefährlich (Schadcode)" sein könnten oder zu viel Platz auf dem Server belegen.
Auftrag: Verhindern, dass der Benutzer problematische Zeichen verwendet. Für Robustheit und Sicherheit sorgen.
Lernziele:
- Validierung von Benutzereingaben durch reguläre Ausdrücke verstehen
- Verstehen, dass eine Prüfung nur am Client nicht ausreicht, falls Quiz-Daten aus einer unbekannten Quelle über ein Server-API in die Datenbank importiert werden
- das Konzept der Mime-Types verstehen
- Sicherheitsaspekte bestimmter Dateiformate erkunden
- Upload-Restriktionen konfigurieren
- Character-Escaping-Rules verstehen und einsetzen
- Parameter-Data-Binding verstehen und einsetzen
Soll man nun anhand des Beispiels den großen Fächer der Möglichkeiten aufmachen, die reguläre Ausdrücke bieten? Bis hin zum Replacement von Teilausdrücken und zu den Feinheiten unterschiedlich aggressiver Matching-Mechanismen? Nein! Wir erläutern so viel, wie für die Aufgabe gebraucht wird. Den Rest muss der Studi sich zuhause oder in einer Arbeitsgruppe allein aneignen. Wir müssen so etwas nicht "vorlesen" in einer Lehrveranstaltung. Aber prüfen sollten wir einige Zeit später ganz unabhängig von der Werkelei am "fertigen Auto", ob die selbständige Wissensaneignung geklappt hat.
4) Programmier-Konzepte
Nicht selten gibt es an Hochschulen einen ideologischen Streit, ob man Studenten am Anfang mit C++, Java, Python, Logo, Prolog oder Lisp konfrontieren sollte. Der Einsatz von AI könnte es erlauben, dass die Studis kleine Aufgaben in mehreren Sprachen parallel umsetzen und die Ergebnisse vergleichen. Vielleicht wäre das ein Weg, allgemeine Konzepte (Lokalität, Sichtbarkeiten, Funktionen, imperativ vs. regelbasiert, ereignisgetrieben, Parameter Passing, Rekursion, …) zu vermitteln, jenseits von Syntax-Stolperfallen. Ohne handwerkliche Sicherheit mit ein oder zwei Programmiersprachen geht es natürlich nicht. Lernen aus Fehlern muss sein.
"OO-Patterns" kann man später dann vielleicht experimentell erkunden, indem man sie anhand von selbst erzeugten Beispielen studiert ("Bau mir ein ganz kleines Beispielsystem, in dem eines der folgenden sieben Patterns vorkommt: … Ich schau mir dann den Code an und rate, welches Pattern du verwendet hast").
5) Algorithmen-Lehre nur für Interessierte
Wer eine elektronische Schaltung entwirft, benutzt 20 oder 30 verschiedene Typen von ICs. Er liest deren Spezifikation und hat dann eine grobe Vorstellung davon, wie es innen drin aussieht. Wer so einen Chip entwirft, ist vermutlich ebenfalls Elektronik-Ingenieur, hat aber einen ganz anderen Hut auf. So ist es auch in der Informatik: Wenige Personen entwerfen eine Library — viele nutzen sie. Informatik-Geschichte ist faszinierend, Donald Knuth fraglos ein großartiger Typ. Aber alles, was in der Praxis gebraucht wird, wurde längst in Libraries gegossen. Genieße es, ein paar Häppchen davon zu verstehen, mit dem ruhigen Bewusstsein, dass deine Uni keinen Prüfungsstoff daraus gemacht hat. Begeisterungsfähige Studis werden Algorithmen aus eigenem Antrieb verstehen wollen, die anderen dürfen davon abstrahieren.
6) Multimedia in der Lehre
Aufbauend auf den Erfahrungen mit der Vorlesung Software Engineering in Industrial Practice (SEIP) an der TU München wurde 2013-2023 die "Multimediale Didaktik" (siehe https://multimediale-didaktik.de/) entwickelt, welche 2023 sogar mit dem Balzert-Preis der Gesellschaft für Informatik (GI) ausgezeichnet wurde.
Der Knackpunkt hierbei ist, gezielt verschiedene multimediale Elemente in der Lehre zu verankern, um eine zeitgemäße Lehre der Generation Z anbieten zu können. Bei Online-Lehrveranstaltungen wird hierbei über 12 gezielte, didaktische Aspekte eine möglichst immersive Lehrerfahrung erzeugt. Etliche Aspekte davon sind auch auf Präsenz-Lehrveranstaltungen übertragbar.
7) Gamification in der Lehre
Lehre sollte Spaß machen, dem Dozenten und den Studenten. Dem Dozenten, damit seine Begeisterung sich auf die Studenten überträgt. Den Studenten, damit sie motiviert bleiben und sich besser an die Lehrinhalte erinnern (Stichwort: positives Gefühl).
Ein wichtiger Aspekt dabei kann Gamification sein. Manchmal von einigen Dozenten sogar eher despektierlich als "unseriöse Aspekte der Lehre" betrachtet, aber auf jeden Fall viel zu sehr verkannt. Richtig dosiert und zielgerichtet eingesetzt, entfaltet Gamification erhebliche Vorteile in der Lehre, wie die Evaluationen der Vorlesung Software Engineering in Industrial Practice (SEIP) an der TU München seit vielen Jahren zeigen. Hier werden insbesondere Multiple-Choice-basierte Quizzes über ein Head-Up Display (HUD) in die Online-Lehrveranstaltung eingeblendet, mit welchen die Studenten mit Hilfe eines neben dem Video-Stream eingeblendeten Pad (eine kleine Web-Anwendung) interagieren können. Siehe die Screenshots direkt unter https://seip.direct/ für ein paar Impressionen.
Es geht aber nicht nur darum, einfach ein paar Fragen zu stellen. Die Quizzes haben verschiedene Aspekte, die entscheidend sind für sowohl Didaktik als auch Gamification: Erstens gehen die Quiz-Fragen "über den Tellerrand" des aktuellen Themas hinaus, d.h. es wird nie direkt nach dem soeben gelehrten Lehrinhalt gefragt, sondern nach verwandten Aspekten aus der Praxis. Zweitens werden die gegebenen Antworten nicht sofort angezeigt, damit die Studenten sich nicht gegenseitig beeinflussen. Drittens wird zum Schluss nicht nur die richtige Antwort markiert, sondern der Dozent geht auch auf alle falschen Antworten explizit ein, da man dadurch ebenfalls etwas lernen kann und die Studenten somit besser verstehen, warum ihre Antworten falsch waren. Viertens werden über ein Punktesystem sowohl die richtigen Antworten als auch die Reaktionszeiten der Antworten belohnt, um einerseits spontane Antworten zu fördern und andererseits über die gesamte Zeitspanne der Lehrveranstaltung das "Wettkampffieber" bei den Studenten aufrecht zu halten.
8) UML als Alltagsbegleiter von Anfang an
Wir beziehen uns hier ganz besonders auf Klassendiagramme (bzw. bei fortgeschrittenen Studis auf Datenbank-Designs) und State-Diagrams, auch auf Use-Cases — aber die klingen quasi automatisch mit an. Das sind Grundpfeiler der Modellierung jeglicher Fachlichkeit. Lasst uns beliebige Alltags-Beispiele nehmen. Und dann üben, üben, üben.
Je absurder, desto besser. Fangen wir mit einem WC-Lüfter an, der mit einem Bewegungsmelder oder mit dem Lichtschalter verbunden ist. Er hat eine Nachlaufzeit aus verständlichen Gründen. Jeder versteht so ein Ding. Was passiert, wenn ich während der Nachlaufzeit nochmal das WC betrete? Wie lange läuft er dann? Wenn die Sicherung draußen war und der Strom zurückkehrt: Was soll passieren? Wie beschreibe ich das gewünschte Verhalten sauber mit Worten? Geht es besser mit Pseudocode oder mit einem Diagramm?
Eine Ampelanlage, super einfach oder? Na ja, lest mal nach, was so eine Anlage tut, wenn sie nachts abgeschaltet wird und frühmorgens wieder aufwacht. Ist wohl doch nicht so trivial… Packen wir das alles wirklich gern in ein einziges Zustandsdiagramm oder lässt sich das irgendwie aufteilen? Und dann kommt da noch ein spezieller Pfeil für Linksabbieger hinzu… Und wollten wir nicht allen Fußgängern gemeinsam grün geben, damit sie diagonal über die Kreuzung laufen können? Der Magistrat der Stadt verlangt bedarfsgesteuerte Ampelzyklen und wir sollen ihm erklären, wo Kontaktschleifen oder Kameras angebracht werden müssen. Welche Technologie ist eigentlich robuster, billiger? Falls es Tools gibt, die ein State-Diagramm animieren, können wir sie einsetzen. Aber Papier und Bleistift sind auch wunderbare Tools.
Wir modellieren unsere Lehrveranstaltung! Hochschule, Fachbereich, Veranstaltungstyp, Lehrperson, Raum, Studierende, .. das geht schnell. Aber dann kommt die Frage: Meinen wir eigentlich die Vorlesung, so wie sie im Verzeichnis steht? Dann ist ihr ein ZeitPLAN zugeordnet, der seinerseits eine gewisse Komplexität hat (Wochentag, Uhrzeit, Ausnahmen für Feiertage; leitet sich der Zeitraum aus dem Semester per Regel ab? Wird er optional zusätzlich individuell festgelegt? ODER meinen wir die heutige Inkarnation dieser Veranstaltung, die ausnahmsweise in einem abweichenden Raum stattfindet? Wie sieht ein Modell aus, das beides darstellen kann? Für welche Art von Software braucht man so ein Modell? Für die Erstellung des Vorlesungsverzeichnisses sicher nicht!
Wenn wir einen Zettel an den Raum hängen: "Heute bitte drei Stockwerke höher": vielleicht niemand. Wenn wir aber eine Handy-App anbieten, dann muss eine Benachrichtigung über die Raumänderung dort hinein. Und die Raumbelegungs-Software muss wohl oder übel vorsehen, dass jemand eine solche Änderung am Vortag dort einträgt. Sie muss auch nachhalten, wann die Benachrichtigung verteilt werden soll. Denn erfahrungsgemäß können Änderungen sich schneller ändern als man denkt. Also nicht gleich alle alarmieren und dann wieder eine zweite Änderung hinterher schicken!
Kurz und gut: Klassendiagramme malen. Ohne Tool! In drei Gruppen. Dann gibt es reihum Reviews und es werden Schwachstellen entdeckt. Ein bisschen Wettbewerb steigert die Energie im Raum deutlich …
9) Agenten-Wettbewerb
Wir stellen eine Alltags-Aufgabe wie z.B. "Zeichne den Kursverlauf des DAX mit Tagesschlusskursen für ein Jahr. Trage zusätzlich die gleitenden Durchschnitte für 20 Tage und 50 Tage ein und markiere die Punkte, an denen sich die beiden geglätteten Kurven schneiden!"
Die Studenten bilden 3er Teams. Jedes Team hat 3 Versuche mit einem Tool seiner Wahl. Das Tool darf gewechselt werden, aber es sind nur drei "Absende-Operationen" erlaubt. Wenn die Studenten das Ziel in drei Anläufen nicht erreichen, dürfen sie mit den Ergebnissen noch 45 Minuten lang manuell weitermachen (Python, Excel …)
Es gibt zahlreiche solche "Vibe-Coding" Wettbewerbe als Youtube Videos. Es kann nicht schaden, vorher ein paar davon anzusehen.
Warum das? Es gibt Standard-Aufgaben, die man mit der richtigen AI oder mit einer Spezial-Website problemlos bewältigen kann. Die menschliche Kompetenz steckt darin, den besten Helfer zu finden — in diesem Fall möglicherweise eine Webseite, die ohnehin auf die Darstellung von Börsendaten spezialisiert ist und sogar passende Einstellmöglichkeiten mitbringt.
Natürlich kann man auch ein Python Script erzeugen lassen. Welche Vorgehensweise ist besser, welches Ergebnis ist hübscher, welche Art der Erstellung ist einfacher benutzbar? Was skaliert besser, wenn ich jeden Tag eine automatische Nachricht in meinem Postfach dazu haben will?
Es kann eine gute Strategie sein, die AI im ersten Schritt gar nicht um die Erfüllung der Aufgabe zu bitten, sondern sie zu fragen, ob es irgendeine kostenfreie Website gibt, wo ich mein Problem besser lösen kann als mit ihr.
Der eigentliche Zweck solcher Übungen ist es, für den (oft zunächst unausgesprochenen) Kontext zu sensibilisieren, in dem eine Anforderung auftaucht, und diesen in die Lösungsstrategie einzubeziehen. Wir stellen uns das so vor, dass zuerst nur die reine inhaltliche Anforderung präsentiert wird und dass Informationen zum Kontext nur auf Nachfrage der Studis gegeben werden (z.B.: soll für alle europäischen Börsenplätze nutzbar sein, soll als Email-Service angeboten werden, Datenquellen liegen bereits vor, die Werte für die Glättung soll jeder Nutzer selbst wählen können, ODER es ist eine einmalige Anfrage eines Vermögenskunden, der möglichst eine Antwort noch während eines laufenden Beratungsgesprächs bekommen soll).
10) Ein differenziertes Bild der KI-Unterstützung
Software-Entwicklung kennt viele Arten von Arbeitsschritten, die sich aber fast alle um "Planning", "Functionality" und "Guidance" drehen. Im Planning arbeiten wir primär mit Prosa (Englisch oder Deutsch), die Funktionalität wird mit Hilfe von Code ausgedrückt und die Guidance besteht üblicherweise aus eingebetteten Kommentaren direkt im Code. Wenn man sich die drei Artefakte Prosa, Code und Kommentare als Zustände vorstellt, so sind die Arten von Arbeitsschritten Zustandsübergänge. Das folgende Diagramm visualisiert dies:
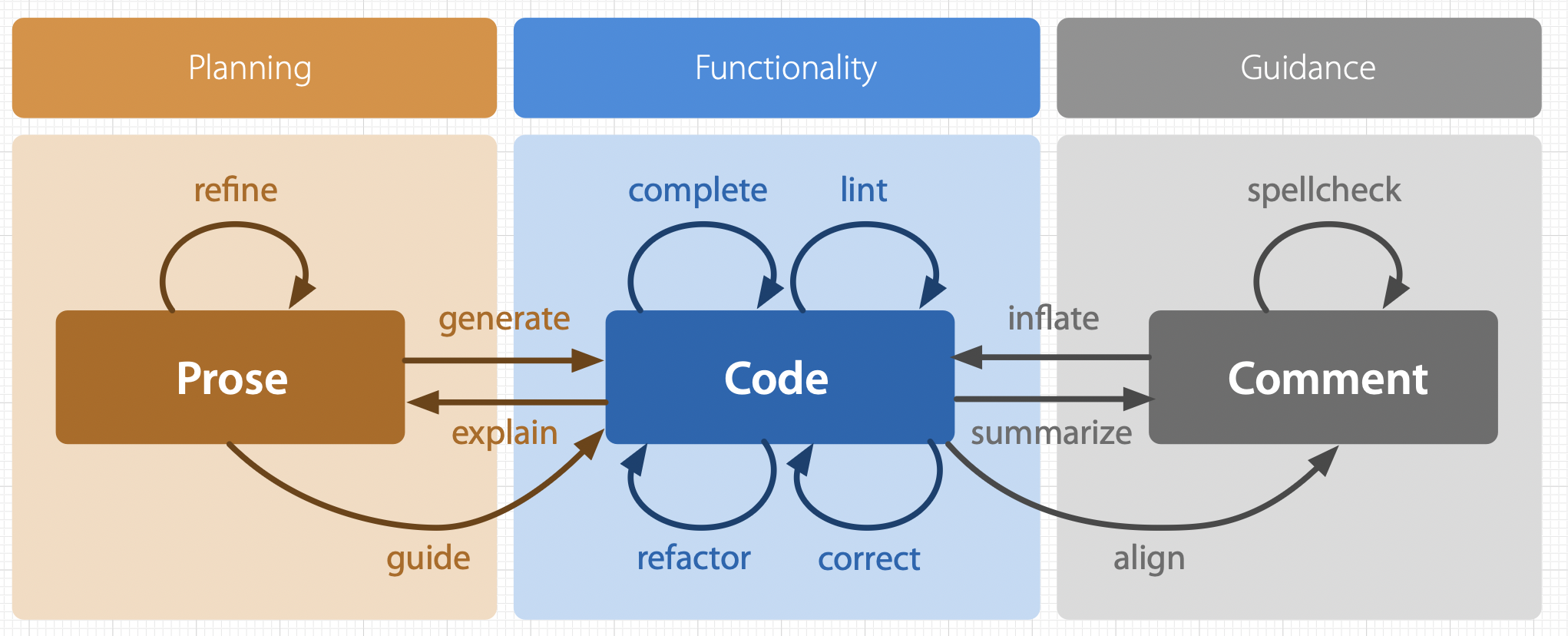
Die These ist, dass alle zwölf dargestellten Arten von Arbeitsschritten durch KI zumindest unterstützt (Stichwort: Assistant), meistens sogar semi-automatisiert (Stichwort: Supervised Agent) oder gar voll-automatisiert (Stichwort: Autonomous Agent) werden können. Der aktuelle Stand der Technik (2025-12) erlaubt bereits die Modi Assistant und Supervised Agent und es entstehen aktuell vermehrt Agents und Frameworks, um auch den Modus Autonomous Agent für diese Schritte realisieren zu können.
Allerdings sind nicht alle Arten von Arbeitsschritten gleich gut unterstützbar oder gar automatisierbar. Deshalb variiert die Produktivitätssteigerung durch KI in der Software-Entwicklung noch sehr stark.
Die folgenden Arbeitsschritte können bereits sehr gut von der KI unterstützt werden: "refine" (schrittweise Verfeinerung eines Plans oder gar Spezifikation), "guide" (Hilfestellungen zu Programmierkonstrukten und APIs), "generate" (Erzeugen von Code aus einer Spezifikation oder eines Plans), "explain" (Erklärung von existierendem Code), "lint" (Qualitätssicherung von Code), "refactor" (struktureller Umbau von Code), "correct" (Korrektur von Code), "summarize" (Zusammenfassung von Code zu einem Kommentar), "align" (Aktualisierung eines Kommentars basierend auf dem veränderten Code) und "spellcheck" (Korrektur des Kommentar-Prosa).
Die folgenden Arbeitsschritte sind inhärent nicht besonders gut KI-unterstützbar: "complete" (Vervollständigung unvollständiger Code-Sequenzen), da hierbei zu viel Halluzination und somit Ablenkung geschieht; und "inflate" (Erzeugen von Code aus einem Kommentar), da aufgrund der üblichen kompakten und abstrahierenden Schreibweise von Kommentaren zu viel Halluzination in den Code kommt. Diese beiden Arbeitsschritte sind allerdings nicht sonderlich dramatisch in der Praxis.
Die größten Produktivitätssteigerungen in der Praxis erfolgen durch KI-unterstütztes "generate" und "refactor". Die größten Verbesserungen in der Code-Qualität erhält man durch KI-unterstütztes "lint". Die größten Motivationsschübe erfahren Software-Entwickler durch KI-unterstütztes "guide".
← Übersicht: Disruption in der IT-Ausbildung | Weiter: Agentic Coding — Ein großes Lehr-Projekt →